本篇文章給大家帶來了關于mysql的相關知識,其中主要介紹了關于索引下推的相關內容,索引條件下推也叫索引下推,英文全稱Index Condition Pushdown,簡稱ICP,用于優化數據查詢,下面一起來看一下,希望對大家有幫助。

程序員必備接口測試調試工具:立即使用
Apipost = Postman + Swagger + Mock + Jmeter
Api設計、調試、文檔、自動化測試工具
后端、前端、測試,同時在線協作,內容實時同步
推薦學習:mysql視頻教程
SELECT 語句執行過程
MySQL 數據庫由 Server 層和 Engine 層組成:
Server層: 有SQL分析器、SQL優化器、SQL執行器,用于負責SQL語句的具體執行過程。Engine層: 負責存儲具體的數據,如最常使用的InnoDB存儲引擎,還有用于在內存中存儲臨時結果集的TempTable引擎。
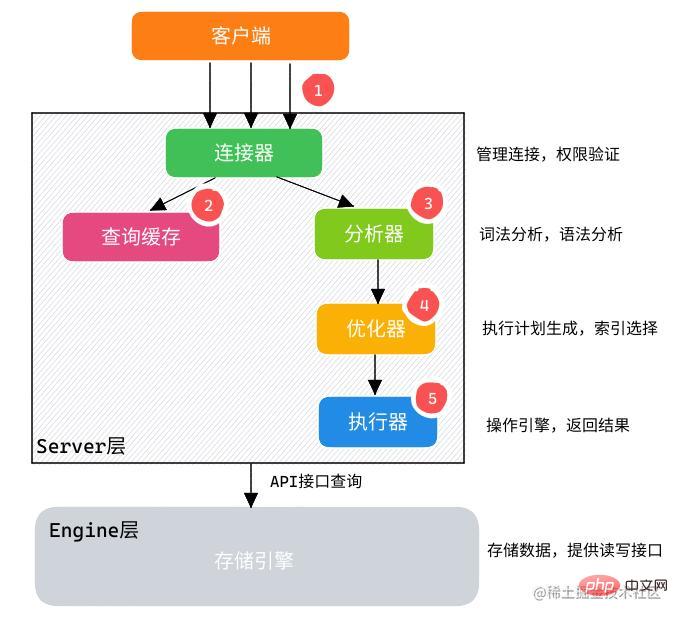
-
通過客戶端/服務器通信協議與
MySQL建立連接。 -
查詢緩存:
- 如果開啟了
Query Cache且在查詢緩存過程中查詢到完全相同的SQL語句,則將查詢結果直接返回給客戶端; - 如果沒有開啟
Query Cache或者沒有查詢到完全相同的SQL語句則會由解析器進行語法語義解析,并生成解析樹。
- 如果開啟了
-
分析器生成新的解析樹。
-
查詢優化器生成執行計劃。
-
查詢執行引擎執行
SQL語句,此時查詢執行引擎會根據SQL語句中表的存儲引擎類型,以及對應的API接口與底層存儲引擎緩存或者物理文件的交互情況,得到查詢結果,由MySQL Server過濾后將查詢結果緩存并返回給客戶端。若開啟了
Query Cache,這時也會將SQL語句和結果完整地保存到Query Cache中,以后若有相同的SQL語句執行則直接返回結果。
Tips:MySQL 8.0 已去掉 query cache(查詢緩存模塊)。
因為查詢緩存的命中率會非常低。 查詢緩存的失效非常頻繁:只要有對一個表的更新,這個表上所有的查詢緩存都會被清空。
什么是索引下推?
索引下推(Index Condition Pushdown): 簡稱 ICP,通過把索引過濾條件下推到存儲引擎,來減少 MySQL 存儲引擎訪問基表的次數 和 MySQL 服務層訪問存儲引擎的次數。
索引下推 VS 覆蓋索引: 其實都是 減少回表的次數,只不過方式不同
-
覆蓋索引: 當索引中包含所需要的字段(
SELECT XXX),則不再回表去查詢字段。 -
索引下推: 對索引中包含的字段先做判斷,直接過濾掉不滿足條件的記錄,減少回表的行數。
要了解 ICP 是如何工作的,先從一個查詢 SQL 開始:
舉個栗子:查詢名字 la 開頭、年齡為 18 的記錄
SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;
有這些記錄:
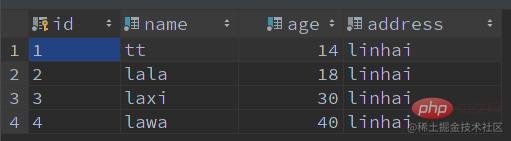
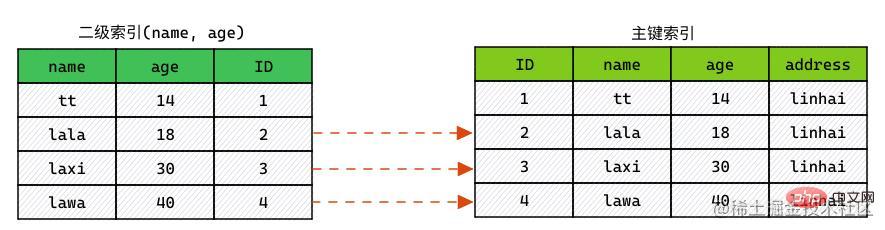
不開啟 ICP 時索引掃描是如何進行的:
- 通過索引元組,定位讀取對應數據行。(實際上:就是回表)
- 對
WHERE中字段做判斷,過濾掉不滿足條件的行。
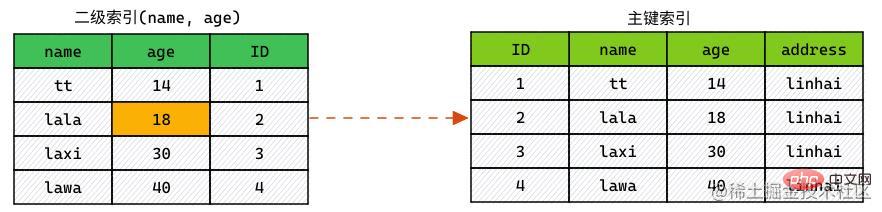
使用 ICP,索引掃描如下進行:
- 獲取索引元組。
- 對
WHERE中字段做判斷,在索引列中進行過濾。 - 對滿足條件的索引,進行回表查詢整行。
- 對
WHERE中字段做判斷,過濾掉不滿足條件的行。
動手實驗:
實驗:使用 MySQL 版本 8.0.16
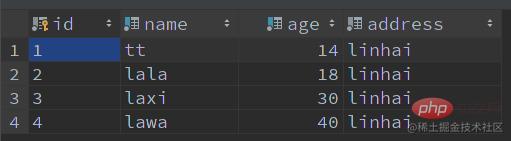
-- 表創建 CREATE TABLE IF NOT EXISTS `user` ( `id` VARCHAR(64) NOT NULL COMMENT '主鍵 id', `name` VARCHAR(50) NOT NULL COMMENT '名字', `age` TINYINT NOT NULL COMMENT '年齡', `address` VARCHAR(100) NOT NULL COMMENT '地址', PRIMARY KEY (id) ) ENGINE=InnoDB DEFAULT CHARSET utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT '用戶表'; -- 創建索引 CREATE INDEX idx_name_age ON user (name, age); -- 新增數據 INSERT INTO user (id, name, age, address) VALUES (1, 'tt', 14, 'linhai'); INSERT INTO user (id, name, age, address) VALUES (2, 'lala', 18, 'linhai'); INSERT INTO user (id, name, age, address) VALUES (3, 'laxi', 30, 'linhai'); INSERT INTO user (id, name, age, address) VALUES (4, 'lawa', 40, 'linhai'); -- 查詢語句 SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;
新增數據如下:
- 關閉
ICP,再調用EXPLAIN查看語句:
-- 將 ICP 關閉 SET optimizer_switch = 'index_condition_pushdown=off'; -- 查看確認 show variables like 'optimizer_switch'; -- 用 EXPLAIN 查看 EXPLAIN SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;

- 開啟
ICP,再調用EXPLAIN查看語句:
-- 將 ICP 打開 SET optimizer_switch = 'index_condition_pushdown=on'; -- 查看確認 show variables like 'optimizer_switch'; -- 用 EXPLAIN 查看 EXPLAIN SELECT * FROM user WHERE name LIKE 'la%' AND age = 18;

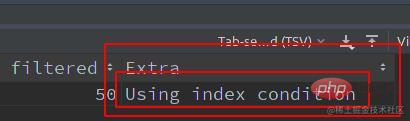
由上實驗可知,區別是否開啟 ICP: Exira 字段中的 Using index condition
更進一步,來看下 ICP 帶來的性能提升:
通過訪問數據文件的次數
-- 1. 清空 status 狀態 flush status; -- 2. 查詢 SELECT * FROM user WHERE name LIKE 'la%' AND age = 18; -- 3. 查看 handler 狀態 show status like '%handler%';
對比開啟 ICP 和 關閉 ICP: 關注 Handler_read_next 的值
-- 開啟 ICP flush status; SELECT * FROM user WHERE name LIKE 'la%' AND age = 18; show status like '%handler%'; +----------------------------|-------+ | Variable_name | Value | +----------------------------|-------+ | Handler_commit | 1 | | Handler_delete | 0 | | Handler_discover | 0 | | Handler_external_lock | 2 | | Handler_mrr_init | 0 | | Handler_prepare | 0 | | Handler_read_first | 0 | | Handler_read_key | 1 | | Handler_read_last | 0 | | Handler_read_next | 1 | <---重點 | Handler_read_prev | 0 | | Handler_read_rnd | 0 | | Handler_read_rnd_next | 0 | | Handler_rollback | 0 | | Handler_savepoint | 0 | | Handler_savepoint_rollback | 0 | | Handler_update | 0 | | Handler_write | 0 | +----------------------------|-------+ 18 rows in set (0.00 sec) -- 關閉 ICP flush status; SELECT * FROM user WHERE name LIKE 'la%' AND age = 18; show status like '%handler%'; +----------------------------|-------+ | Variable_name | Value | +----------------------------|-------+ | Handler_commit | 1 | | Handler_delete | 0 | | Handler_discover | 0 | | Handler_external_lock | 2 | | Handler_mrr_init | 0 | | Handler_prepare | 0 | | Handler_read_first | 0 | | Handler_read_key | 1 | | Handler_read_last | 0 | | Handler_read_next | 3 | <---重點 | Handler_read_prev | 0 | | Handler_read_rnd | 0 | | Handler_read_rnd_next | 0 | | Handler_rollback | 0 | | Handler_savepoint | 0 | | Handler_savepoint_rollback | 0 | | Handler_update | 0 | | Handler_write | 0 | +----------------------------|-------+ 18 rows in set (0.00 sec)
由上實驗可知:
- 開啟
ICP:Handler_read_next等于 1,回表查 1 次。 - 關閉
ICP:Handler_read_next等于 3,回表查 3 次。
這實驗跟上面的栗子就對應上了。
索引下推限制
根據官網可知,索引下推 受以下條件限制:
-
當需要訪問整個表行時,
ICP用于range、ref、eq_ref和ref_or_null -
ICP可以用于InnoDB和MyISAM表,包括分區表InnoDB和MyISAM表。 -
對于
InnoDB表,ICP僅用于二級索引。ICP的目標是減少全行讀取次數,從而減少I/O操作。對于InnoDB聚集索引,完整的記錄已經讀入InnoDB緩沖區。在這種情況下使用ICP不會減少I/O。 -
在虛擬生成列上創建的二級索引不支持
ICP。InnoDB支持虛擬生成列的二級索引。 -
引用子查詢的條件不能下推。
-
引用存儲功能的條件不能被按下。存儲引擎不能調用存儲的函數。
-
觸發條件不能下推。
-
不能將條件下推到包含對系統變量的引用的派生表。(
MySQL 8.0.30及更高版本)。
小結下:
ICP僅適用于 二級索引。ICP目標是 減少回表查詢。ICP對聯合索引的部分列模糊查詢非常有效。
拓展:虛擬列
CREATE TABLE UserLogin ( userId BIGINT, loginInfo JSON, cellphone VARCHAR(255) AS (loginInfo->>"$.cellphone"), PRIMARY KEY(userId), UNIQUE KEY idx_cellphone(cellphone) );
列 cellphone :就是一個虛擬列,它是由后面的函數表達式計算而成,本身這個列不占用任何的存儲空間,而索引 idx_cellphone 實質是一個函數索引。
好處: 在寫 SQL 時可以直接使用這個虛擬列,而不用寫冗長的函數。
舉個栗子: 查詢手機號
-- 不用虛擬列 SELECT * FROM UserLogin WHERE loginInfo->>"$.cellphone" = '13988888888' -- 使用虛擬列 SELECT * FROM UserLogin WHERE cellphone = '13988888888'
推薦學習:mysql視頻教程
