

相關學習推薦:mysql教程
不能說不行
今天加班,業務的妹子過來找我們查數據,說數據查出來量不對。一看妹子的SQL是這樣寫的:
select distinct * from prvt_pub_stmt_vnwhere issue_time >= '2020-08-01'and issue_time <= '2020-08-01'and prs_dmtd_cde in ('p','n');復制代碼
我分析來分析去,感覺沒有問題呀,于是查了一下prs_dmtd_cde 字段的碼值,發現不僅有大寫的P還有小寫的p,而妹子只查了小寫的p,數據量卻多了很多。
于是我就把妹子的SQL改了一下:
select distinct * from prvt_pub_stmt_vnwhere issue_time >= '2020-08-01'and issue_time <= '2020-08-01'and prs_dmtd_cde in ('p','n','P','N');復制代碼
查出來的結果竟然是一樣的。這就。。。
在妹子面前當然不能說不行啊,于是讓妹子先回去再看看。
我這邊飛快的上網查了查,發現竟然是MySQL 的編碼格式和排序規則的問題。
知其所以然
我們MySQL數據庫基本上用的都是 utf8 的編碼格式,而 utf8 編碼格式還存在各種排序規則。常用的如下:
utf8_bin:將字符串中的每一個字符以十六進制方式存儲數據,區分大小寫。
utf8_general_ci:不區分大小寫,ci為case insensitive的縮寫,即大小寫不敏感。
再查一下默認的字符集設置:
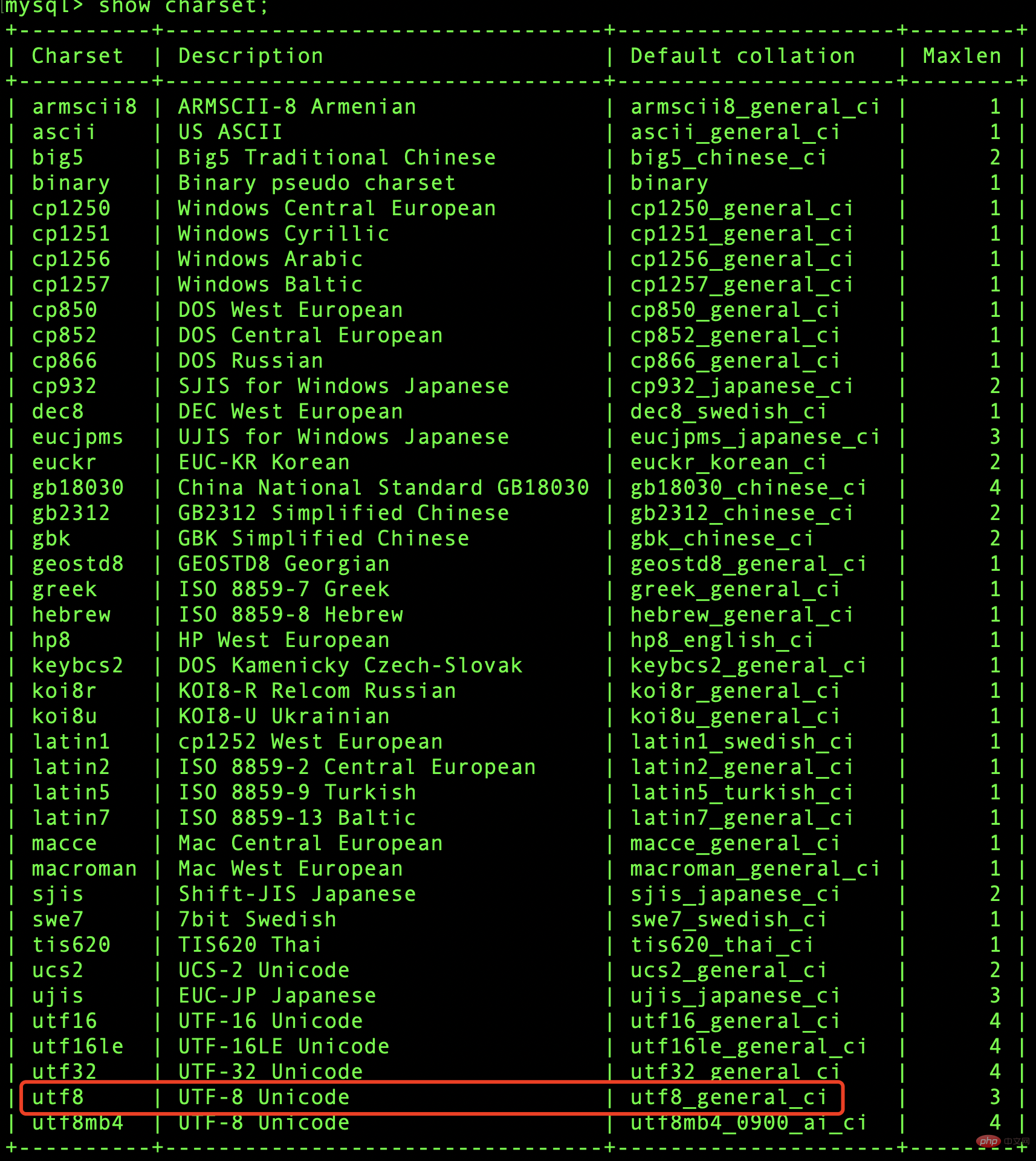
剛好 utf8 編碼格式的默認排序規則就是:utf8_general_ci——即不區分大小寫。
解決方案
問題原因找到了,那就對癥下藥好了。
解決方法自然就是直接修改字段的 collate 屬性為 utf8_bin。
ALTER TABLE prvt_pub_stmt_vn CHANGE prs_dmtd_cde prs_dmtd_cde VARCHAR(255) CHARACTER SET utf8 COLLATE utf8_bin;復制代碼
另外還有一種解決方法,就是不改變原有表結構,而是改SQL。在查詢字段前加上 binary 關鍵字。
select distinct * from prvt_pub_stmt_vnwhere issue_time >= '2020-08-01'and issue_time <= '2020-08-01'and binary prs_dmtd_cde in ('p','n');復制代碼
Mysql 默認查詢是不分大小寫的,可以在 SQL 語句中加入 binary 來區分大小寫。
binary 不是函數,是類型轉換運算符,它用來強制它后面的字符串為一個二進制字符串,可以理解為在字符串比較的時候區分大小寫。
最后
問題解決了,當然是去告訴妹子這個問題多么多么深奧,我又是如何剖析原理最終解決的了。
看著妹子投來的崇拜目光,當然是很開心了。
最最重要的還是要記住這個問題,以后在遇到字段大小寫敏感的業務,建表的時候要注意字符集和排序規則的選擇,以避免今天這種事情的發生。
想了解
